
Diving into the technical details of Bluesky
Interested in Bluesky and ATProto? Me too! Here are some of the things I learned.

In November 2022, I migrated from Twitter to Mastodon. Since then, I also started administering a Mastodon server, and have gotten much more into the technical details of hosting services. I semi-understand ActivityPub, which Mastodon is built on – so I wondered, how does Bluesky actually work?
Oddly enough, I found Bluesky harder to understand than Mastodon – this may be because I dove into the rabbit hole more rapidly, because it is a more layered technical architecture, or the fact that it is in need of well edited documentation.
Nonetheless, in this blog post I try to compact my learnings for personal and public reference. It remains a long one, because there's a lot to it.
Bluesky the application
When I use Bluesky, I am interfacing with an application. That means it is taking actions on my behalf, which is nothing new. Usually, web services will take the action of reading and writing my actions to their database. If I used Twitter, I would post to their databases. When I post on Mastodon, I post to the Mastodon server I am on. My data is entered into the application database.
This is where Bluesky gets interesting: When I log in to Bluesky, I authorize it to become my steward, allowing it to read and write my data. This time however, it is reading from and writing to my personal database, not the application's database. This personal database is called the Personal Data Store (PDS).
The hidden complexity of Personal Data Stores
We may own our data because it is in a Personal Data Store (PDS), but where is this thing? When I sign up to Bluesky, I do not need to do anything, which is great. It also means there is something additional happening.
Behind the scenes, what happens is that Bluesky creates a Data Store on my behalf on one of their servers. Hosting my own Data Store is possible: Bluesky makes their PDS source code openly available. Out of curiosity, I looked into the numbers and it appears most people do outsource this to Bluesky.
To be more exact, I provide some descriptors of the published dataset. Specifically, 11,712,175 people host their data stores with Bluesky compared to 59,272 who host it elsewhere (as of August 5th, 2025). Bluesky operates 81 communal data stores, which evens out to roughly 144,595 accounts per data store. I would hardly call sharing something with that many people personal. The remaining 59,272 are hosted on 2,200 data stores all across the web.
Up to here, it is manageable. Bluesky is an application that writes data to your data store, not to a database. Most people host their data store with Bluesky.
On to the next question: How does Bluesky, or any application, know how to read and write data to your Data Store?
This is where the Authenticated Transfer Protocol (AT Protocol) comes in as the glue. The AT Protocol specifies many things, including (1) Where a person's Data Store is located and (2) How data that is read and written to it should look like, and (3) How to give applications like Bluesky access to write to your Data Store.
Where is your Data Store located?
When we visit a website, we go to something like https://google.com. This tells us to use the https protocol and there is a specific procedure to figure out what this google.com thingy is supposed to lead to. Website domains are focused on being human-readable, because they need to be memorable.
Within the AT Protocol, Data Stores are addressed in a way that is not memorable: at://did:plc:2xau7wbgdq4phuou2ypwuen7. Breaking this down quickly increases in complexity, so bear with me.
- The protocol is specified as
at://for AT Protocol didstands for Decentralized Identifier, which is the same for every Data Storeplcstands for Public Ledger of Credentials, which is also the same for every Data Store2xau7wbgdq4phuou2ypwuen7is a unique string with 24 characters that identifies your Data Store
With this information, we can find the data store and read all the public information without issue. It is not necessarily user friendly to look at a Data Store directly, but it is possible (and informative!).
One crucial note: The "Public Ledger of Credentials" is like a lookup registry for the 24 character string. That registry needs to be managed by someone, and right now, that is Bluesky. Also, if you look up a Data Store address in the wrong registry, you will not find where it is located. In other words, we always need one or multiple registries to tell people where our Data Stores actually are, but preferably it is super clear which registry I need to look you up in. Again, Bluesky makes the source code available to run your own registry, but more registries is not necessarily a good thing in this system.
How does the data in your Data Store look like?
A Data Store is a container for all kinds of information, which the AT Protocol helps organize.
First off, AT Protocol standardizes how application data is stored. Each application makes its own paths/folders, following what is called "Reverse DNS" naming. Here application data for https://bsky.app follows the app.bsky format. Any path starting with app.bsky belongs to this application (for example, app.bsky.feed.post). One application can have many such paths. For example, Bluesky has the following (among many more):
app.bsky.actor.profileapp.bsky.graph.followapp.bsky.feed.postapp.bsky.feed.likeapp.bsky.feed.repost
These are all records that are in your Data Store. This can become somewhat peculiar when you want to build another application using the same data. For example, if I were to build PurpleSky.com, I would have to use the application data stored in folders starting with app.bsky to be interoperable with Bluesky. This is only a software engineering consideration, however.
Secondly, AT Protocol specifies what each bit of application data should look like. These expectations are formulated in a schema, which tells us exactly what to expect. We can even validate whether the data we read is conform to the schema. For example, you might say that the username must be a string of characters without any special symbols like @<>+", which would mean a username of test@example would not be valid but test_example would be. The AT Protocol calls these schemas "Lexicons." Schema is a predefined term in software, where you specifically say what structure and content the data must have. For example, a like on Bluesky must have the subject of the like (unique post identifier) and when the like was created (a date-time). Only when both of these are present, can a like be valid according to the schema.
How to give an application write access?
We now know how application data is saved in a Data Store, but we still need to be able to give applications such as Bluesky permission to write to our Data Store. In order to do so, we log in to our Data Store using a so called Open Authentication (OAUTH) procedure, which grants Bluesky with a temporary session to write to our Data Store.
Our Data Store in essence, becomes our single sign on for all applications built on top of the AT Protocol. Applications do not need to know your password, and only need to receive the appropriate tokens to read/write to your Data Store.
How are Data Stores consolidated?
The AT Protocol specifies everything around individual Data Stores, but given that there can be hundreds, thousands, or even millions of Data Stores in total, we are faced with the issue of visibility. If my application, for example Bluesky, only knows about my Data Store, it would be a lonely place. I want to be able to see posts by others! And the AT Protocol says nothing about how to do this.
Bluesky offers one approach to how to handle this.
Relay
Bluesky offers a so-called Relay service, which consumes all posts, likes, and other activity for app.bsky application data, for all the Data Stores it knows about. It is important to note that any application data that follows the Bluesky schema, but that Bluesky does not know about, will not be available on Bluesky. Bluesky is a required intermediary in that sense, at this point in time. The source code to create your own relay, is openly available. Note however, that the authoritative relay for Bluesky, the application, is the relay operated by Bluesky. Practically speaking, Bluesky blends the infrastructure layer and app layer under its own name, making it a vertically integrated monopoly where competition is virtually impossible unless the infrastructure layer is decoupled.
This centralizing register (the relay) of all activity permits comprehensive visibility of posts on the Bluesky application, which is a design decision that has its benefits and drawbacks. The relay is another vector of control, alongside the lookup registry for the Data Store addresses, which raises questions around how decentralized the infrastructure truly is. Nonetheless, from an application perspective, being able to search for something and knowing that your results are likely to be complete, is also helpful.
One final note is that the Bluesky Relay is the central register, which can be consumed in different ways. Two different representations of the same data are the "Firehose" (binary notation) and "Jetstream" (JSON notation). This took me a few hours to figure out.
What are some implications of Bluesky's technical setup?
Bluesky is doing a great job at open-sourcing production code, operated at a large scale. They are dealing with incredible growth challenges. I wonder how they're going to keep this up and monetize to keep their Venture Capital backers happy.
I am not an ActivityPub or AT Protocol fan per se. I am mostly curious about them and how their technical decisions lead to social realities. I am uncertain how resilient the AT Protocol network is, when critical pieces of infrastructure are open-source but rely on the authoritative Bluesky source. Bluesky (the corporation) remains the point of failure at this time for Bluesky (the social media). Especially for the Public Ledger of Credentials (the lookup registry of Data Stores), more ledgers does not necessarily lead to easier lookups. Currently, those ledgers do not have standard way to be reconciled in a consistent manner.
As a result, Bluesky is in a bind: If its social media is to be truly decentralized, its infrastructure needs to become more fragmented. But in order to become more fragmented, Bluesky must find ways to meaningfully cede infrastructural control that are critical to its operations. If ATProto serves as an App Data Store, which Bluesky uses and others can use for their apps too, all of this is moot because Bluesky itself is not decentralized. Bluesky needs to make a choice whether it wants to be truly decentralized or merely builds an app on a decentralized protocol. Currently it is building an app on a decentralized protocol.
I want Bluesky to be decentralized, which requires further fragmentation. As its ecosystem currently stands, fragmentation is likely to result in information islands. Registries are so fundamental, an application using a registry is comparable to a Internet Service Providers, but the registry itself is comparable to the internet. In the early days of networked computing, the Western internet and Soviet Union runet were mostly incompatible. The universality of the internet – that the internet you and I access is fundamentally the same – is upheld by communal governance. Bluesky (the corporation) is taking a shortcut as a first-mover – there is no fragmentation, hence, no need for communal governance. Yet, fragmentation is hampered by that same point. There is no fragmentation which can dispute the universality of their authoritative registry, because they hold an effective monopoly. Regardless, decentralization desires fragmentation, so Bluesky's ecosystem and governance must evolve to deal with this at some point.
Bluesky cannot rely solely on ATProto's decentralized and flexible nature to keep the centralizing tendencies of Bluesky's application needs at bay.
Wrapping up
My attempts to understand how Bluesky operates may well be limited. I was already informed that Bluesky's unofficial statistics, provided by Bluesky's infrastructure engineer Jaz, say there are >38 million users on Bluesky. Compared to my estimated ~12 million, there is a big difference that I don't fully understand. This exemplifies that what I write here needs to be evaluated critically and curiously. Build up your own understanding, don't simply accept mine :)
Upon nearly finishing this post, I also found this overview diagram that summarizes the technical bits and bops fairly well, in my opinion:
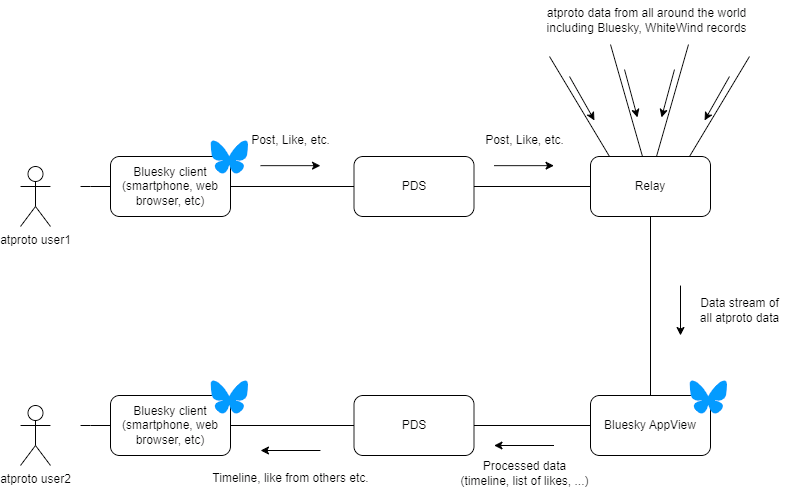
I would love to hear feedback on where I got things wrong and why, so that I can keep learning about this new set of technologies! If you are interested in this topic, let me know and I will write more on this 😊



Comments ()